Pour faire suite à mon précédent billet, voici un petit aperçu de choses avec lesquelles je « joue ».
Le linking, tout le monde aujourd’hui semble en avoir peur.
La faute à Penguin, et surtout à la guerre psychologique menée par Big G.
Pourtant, si l’on a suivi les explications de Sylvain Peyronnet sur les schémas de linking, on comprend mieux comment Google peut détecter, dès le crawl, certains schémas de linking… mais aussi, l’incapacité à détecter d’autres schémas (je laisse la charge de la preuve mathématique à Sylvain, il comprend et fait ça mieux que moi).
On peut donc construire des schémas de linking « aléatoires », via des algorithmes spécifiques, qui ne seront pas évident à détecter
(bien sur, si vous abusez des ancres identiques, ça se verra, mais pas par le schéma de linking lui même).
Dans « la vraie vie », ie sur le web, les liens ne suivent pas une pyramide, comme ce qu’on fait naïvement avec des satellites de niveau 1 puis 2.
Il ne s’agit pas non plus de graphes « aléatoires », type plat de spaghetti.
Les « vrais » graphes obéissent notamment à une loi de puissance (comme pour la longue traîne).
On peut construire, artificiellement, des graphes semblant « naturels ».
Ex, avec l’algorithme de Barabasi-Albert :
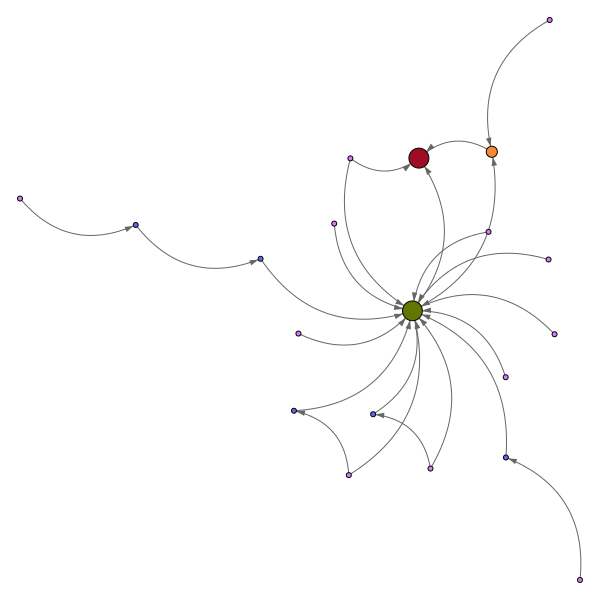
ou encore


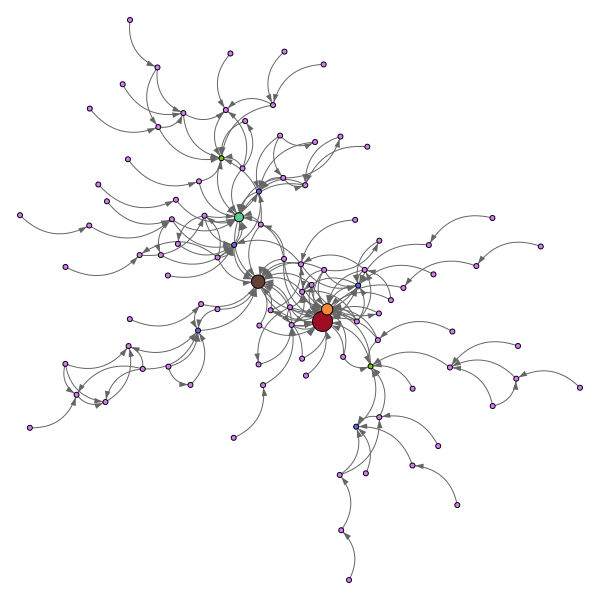
et avec une centaine de pages, ça peut donner ça :

Une difficulté, quand on a généré ce type de réseau, c’est de savoir quelles sont les pages les plus puissantes (en terme de PageRank).
on peut tout considérer au même niveau, mais autant identifier là où ça « pousse » le plus pour faire du boulot propre, et les autres pages de manière plus générique.
Pour cela, sur les graphiques de cet article j’ai fait tourner l’algorithme du pagerank, pour mettre en évidence le PR (interne au réseau, en le considérant isolé du reste) de chaque page. La couleur et la taille de chaque page rendent compte de ce PR.
Les autres métriques dont l’on peut avoir besoin sont également calculables.
De là, un algorithme de spatialisation permet de visualiser le réseau, et il n’y a plus qu’à mettre en application.
Ce sont des manips que l’on peut faire « à la main » de bout en bout avec Gephi, par exemple.
En ce qui me concerne, j’ai codé de petits scripts qui me génèrent tout ce qu’il faut selon différents paramètres et algos, et ça me sort tout cuit le graphe, les PRs, l’image…
S’il y a un intérêt pour ce genre de choses, la mise à disposition d’une API est possible, faites signe !
Par exemple, on peut aussi utiliser un algorithme de type « small world », qui donne des choses comme ça :
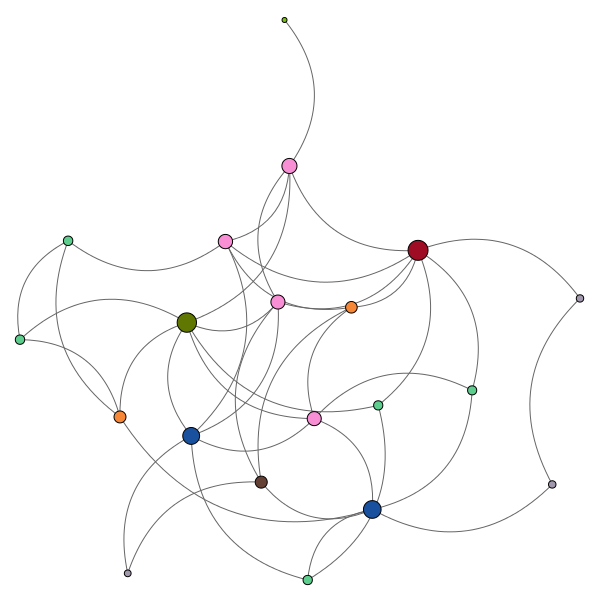
(pour tous ces graphes, on peut jouer avec plusieurs paramètres selon ce qu’on veut)
Ou encore une distribution qui obéit à une loi de puissance :

ou
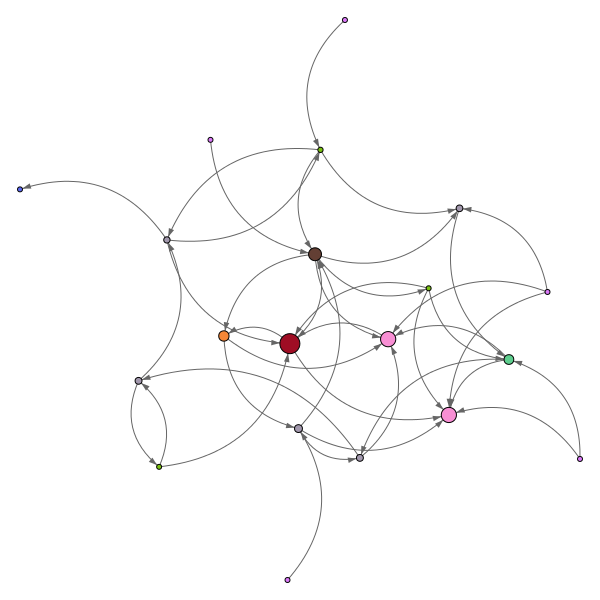
et avec 100 pages, accrochez-vous :

Pour d’autres utilisations, par exemple pour relayer des infos sur les réseaux sociaux, ou pour simuler une diffusion virale d’un texte, l’annonce d’un produit, on peut utiliser des algorithmes de type « feu de forêt ».
Ici encore, pas mal de paramètres, mais la visualisation est parlante :
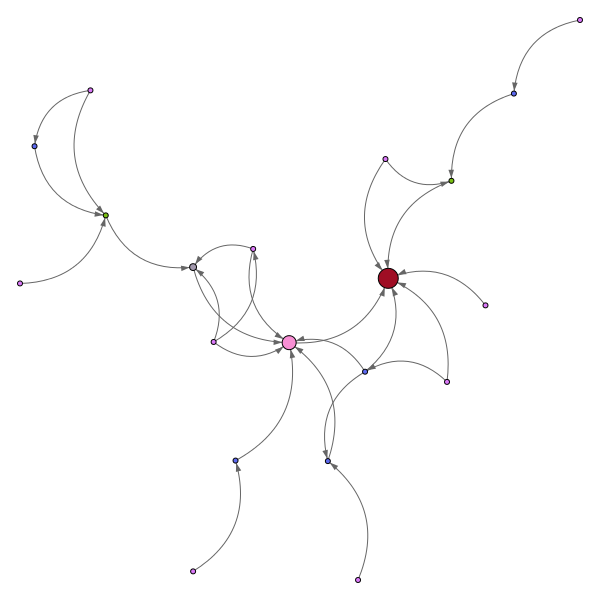
avec 100 intervenants :
ou (strictement mêmes paramètres, mais autre run de l’outil)

et avec 500 pour aller vers le top tweet ? go :

Pour ce type d’utilisation, l’aspect temporel est important: on peut construire le graphe au fil du temps.
Voilà donc une brique, disponible sous forme d’API, (que l’on peut donc intégrer dans un flux automatisé) qui donne du fil à retordre à big G et nous donne un peu de mou pour linker en paix.
J’attends de pied ferme la conf live des frères Peyronnet pour voir si je me plante et comment faire mieux ou plus, et je concrétise tout ça avec un tool public s’il y a suffisamment de gens motivés.
(Grand merci au passage à Sylvain Peyronnet pour sa masterclass et toutes les bonnes idées qu’il sème !)
Et vous, vous « jouez » avec ce genre de choses, ça vous parle ou bien vous considérez que c’est juste de la branlette de matheux ?
Un tool pour construire à la volée des réseaux de linking indétectable, ça vous motive ou rien çà cirer ?
2 questions:
1/ Quel outil utilises-tu pour retrouver le PR de chaque page ?
2/ Ne serait-il plus intéressant d’utiliser PA ou TF de la page au lieu du PR ?
Bonjour Alexandre,
Ici, on considère les réseaux comme « isolés ».
1/Le PR dont je parle n’est pas le PR donné par la Google bar, mais le « vrai » PR issu de l’algorithme initial de Google, basé sur le marcheur aléatoire http://fr.wikipedia.org/wiki/PageRank
Il y a plusieurs algorithmes pour calculer une valeur approchée du PR d’un graphe, notamment par itérations.
Pas d’outil donc, juste un bout de code qui calcule.
2/ Dans ce contexte, le TF n’a pas de sens. Le réseau est isolé, il ne reçoit pas de liens de l’extérieur (on ne connait donc pas les sites ni les thématiques qui amènent les liens)
et on ne connait pas non plus le contenu des pages (elles n’existent pas encore), donc on ne peut pas calculer de TF, ni PA etc.
Par contre, si on ajoute aux données le contenu des pages, on peut améliorer l’aperçu en calculant non plus le PR, mais un PR thématique, qui va prendre en compte le contenu des pages source ert cible d’un lien pour décider de l’ampleur du PR transmis via ce lien.
C’est un peu overkill.
Ici, l’idée est « juste » de partir d’un « bon » (algorithmiquement sous le radar) schéma de linking, en ayant identifié les pages les plus puissantes, pour optimiser le linking d’un site ou d’un satellite.
On peut supposer que les contenus qui seront publiés sur ce réseau seront thématisés (donc PR similaire à PR sémantique).
Ca reste bien sur imparfait par beaucoup d’aspects, mais c’est tout de même bien plus efficace que des méthodes bateau.
Article sympa, on voit que tu as bossé la dernière partie de la MasterClass 🙂
Je pense que l’outil que tu proposes serait super utile. En effet, on voit énormément de chose durant la formation, mais quand on est dans l’opérationnel, c’est dur de trouver le temps de tout mettre en place.
De plus ton outil devrait intéresser n’importe qui est concerné par le linking.
Salut Sylvain,
Ton approche est intéressante, ça fait pas mal de temps que j’essaye de « simuler le naturel ». En plus de donner du fil à retordre à Google ça permet de brouiller les trackers de BL comme Majestic ou Ahrefs. À ce propos d’ailleurs il pourrait être intéressant de « casser » certaines mailles de ces schémas quand les trackers pointent leur nez.
Ça impliquerait d’avoir la main sur une partie des sites qui forment le linking mais ça ajouterait une once de discrétion.
@Manu : oui bien sur, ici je ne parle que d’une facette bien précise (le graph de linking), mais les techniques comme du « cloaking » pour cacher les liens aux crawlers de backlinks sont tout à fait d’actualité (dans tous les cas).
Je trouve le concept très intéressant. Maximiser la popularité, simuler le naturel… à utiliser à bon escient afin de renforcer un travail propre.